Scikit-learn : 분류 - 하이퍼 파라미터(hyper-parameter)
- 학숩 프로세스를 제어하는 파라미터
- 사람이 값을 결정해서 입력해준다.
- 모델 생성 시의 파라미터는 모두 하이퍼 파라미터로 생각하면 됨
# random_state : 하이퍼 파라미터 튜닝 시 고정해야 함 (성능에 영향을 준 파라미터가 어떤 것인지를 알기 위해)
# n_jobs : 사용할 CPU 개수. -1이면 모든 CPU 사용
sgdc = SGDClassifier(penalty='elasticnet', random_state=0, n_jobs=-1)
sgdc.fit(x_train, y_train)
'''출력
SGDClassifier(alpha=0.0001, average=False, class_weight=None,
early_stopping=False, epsilon=0.1, eta0=0.0, fit_intercept=True,
l1_ratio=0.15, learning_rate='optimal', loss='hinge',
max_iter=1000, n_iter_no_change=5, n_jobs=-1,
penalty='elasticnet', power_t=0.5, random_state=0, shuffle=True,
tol=0.001, validation_fraction=0.1, verbose=0, warm_start=False)
'''
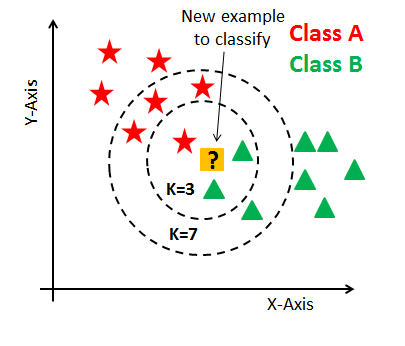
Scikit-learn : 분류 - KNeighborsClassifier(최근접 이웃 알고리즘)
- n_neighbors에 지정된 수의 학습 데이터중 많은 수를 차지하는 쪽으로 테스트 데이터를 분류한다.
- 일반적으로 n_neighbors 파라미터는 동점 확률 문제로 홀수를 사용한다.
- wikipedia : K-최근접 이웃 알고리즘
from sklearn.neighbors import KNeighborsClassifier
knc = KNeighborsClassifier()
knc.fit(x_train, y_train)
'''출력
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
'''
knc_predict = knc.predict(x_valid)
(knc_predict == y_valid).mean()
'''출력
0.9473684210526315
'''
knc = KNeighborsClassifier(n_neighbors=15)
knc.fit(x_train, y_train)
'''출력
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=15, p=2,
weights='uniform')
'''
knc_predict = knc.predict(x_valid)
(knc_predict == y_valid).mean()
'''출력
0.9473684210526315
'''
[]: https://ko.wikipedia.org/wiki/K-최근접_이웃_알고리즘