import warnings
import pandas as pd
from sklearn.datasets import load_iris
# Iris 데이터 세트 로드
iris = load_iris()
# 로드된 원본 데이터에서 피쳐 데이터 부분만 추출
data = iris['data']
# 피쳐 이름 부분 추출
feature_names = iris['feature_names']
# label 부분 추출
target = iris['target']
# Iris 데이터 세트 데이터 프레임 만들기
df_iris = pd.DataFrame(data, columns=feature_names)
# 데이터 프레임에 label 합치기
df_iris['target'] = target
# 훈련 데이터와 테스트 데이터 분리
from sklearn.model_selection import train_test_split
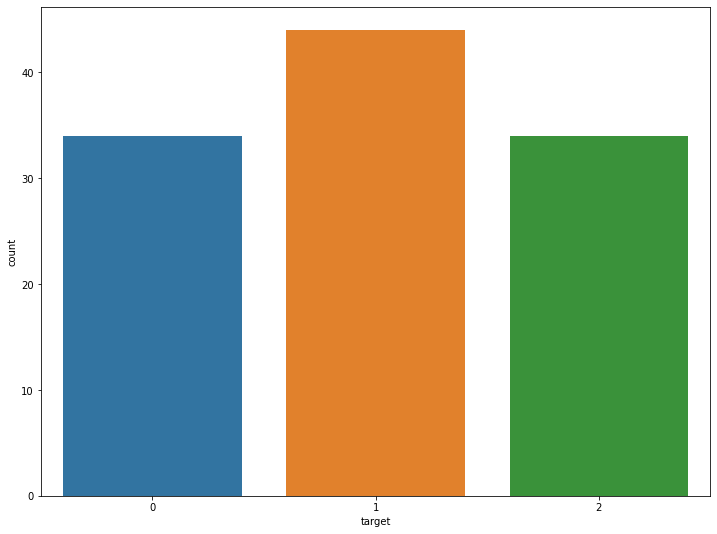
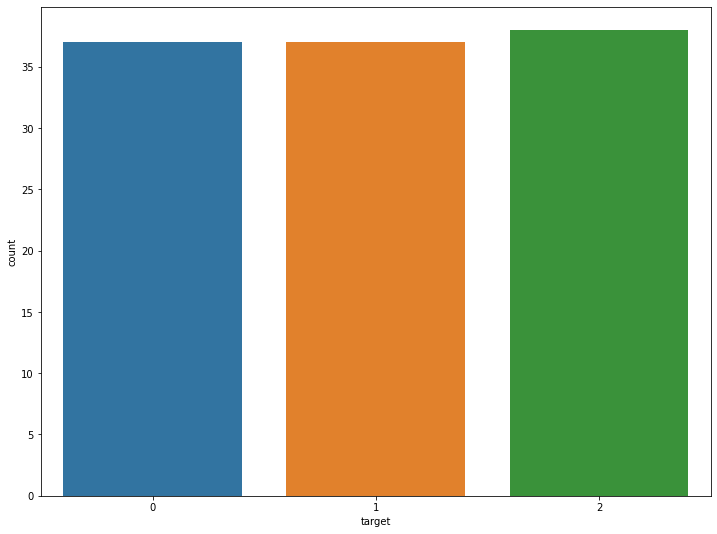
x_train, x_valid, y_train, y_valid = train_test_split(df_iris.drop('target', 1), df_iris['target'])
x_train.shape, y_train.shape
'''출력
((112, 4), (112,))
'''
x_valid.shape, y_valid.shape
'''출력
((38, 4), (38,))
'''
# 시각화 해보기
sns.countplot(y_train)